Analog Photography Assistant - 1.2.0
February 13 2026 · analog-photography-assistant
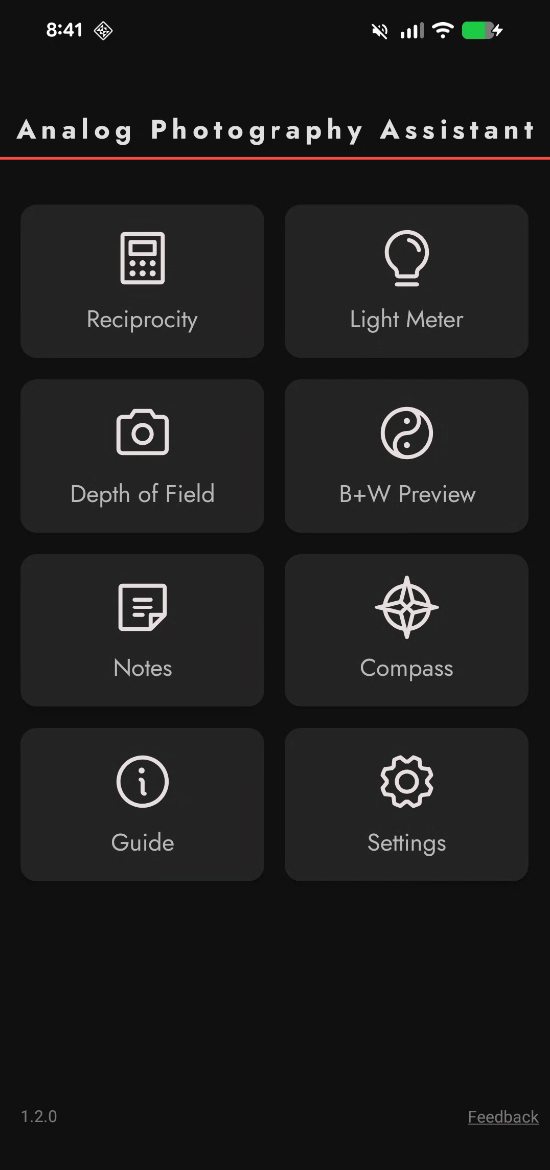

Analog Photography Assistant (APA) is a free, ad-free, privacy-first android app for film photographers. I have just released v1.2.0 which introduces a Depth of Field Calculator . With this you can calculate:
- DoF from the film plane — The nearest and farthest points that will be acceptably sharp, measured from the film plane.
- DoF from the subject — How far the zone of acceptable sharpness extends in front of and behind your focus point.
- Hyperfocal …





