Continuous Delivery is a way of working which ensures our code is always in a releasable state. It encourages us to commit small iterative changes to our codebase, ensuring we are delivering value quickly to our customers and the likelihood of change failures and subsequent re-work is low. From a technical point of view master branch is always releasable. Deployments are kicked off manually by clicking a button.
Continuous Deployment takes this a step further. As soon as code has been committed to master and automated checks have passed the project automatically deploys to production. In practice this saves the development team a huge amount of time; deployments are now automatic and your team gets hours of their week back. At a technical level Continuous Deployment requires complete trust in the software development process, deployment pipeline, quality of automated tests, and observability tools which verify a deployment.
In my product team at work we practice Continuous Deployment. Once a commit lands in master in just 15 minutes it has been fully tested and is in production. Pull Requests are optional; we also develop with pure Trunk Based Development and can all spin up an ephemeral development environment and run all static analysis and tests locally.
A key for us in enabling Continuous Deployment and Trunk Based Development is the open source tool Batect . It provides a fast and consistent way to run development and integration tasks everywhere by running tasks in Docker containers. In this post I explore three DevOps practices and how we’ve applied them using the tool Batect. Specifically:
- Development Environments - Reproducible, immutable, and as close to production as possible.
- Optimise for Developer Experience - Make the day to day tasks we run easy.
- Simplify the build pipeline - Whatever runs in CI can be run locally.
Development Environments
Development Environments are the languages, frameworks, APIs, and databases that we need in order to work on an application. In many projects this must be setup manually. If we’re lucky there is documentation specifying what we need to install, and if we’re really lucky that documentation is up to date. It’s tempting to think that setting up a Development Environment is a one-time setup cost but in my experience it is always evolving; languages, frameworks, and APIs are always slowly changing.
It’s essential that everyone on the team has the same environment. When writing software we have a setup of assumptions about the system. If members of the development team have different versions of APIs and databases installed on their workstations then their mental models of the system are all going to be different before any code is written! Over time software versions drift and the problem gets worse. This leads to the “it works on my machine” phenomena. What if any developer could run the shell command ./batect runDependencies and the entire dependency stack of the application would be started on their workstation.
We want a reproducible development environment; one that can be created anywhere on-demand. We set a rule for the project: every single dependency must run in a Docker container. You can do this with Docker Compose but here we’ll use Batect. Batect provides a much more powerful abstraction than Docker Compose.
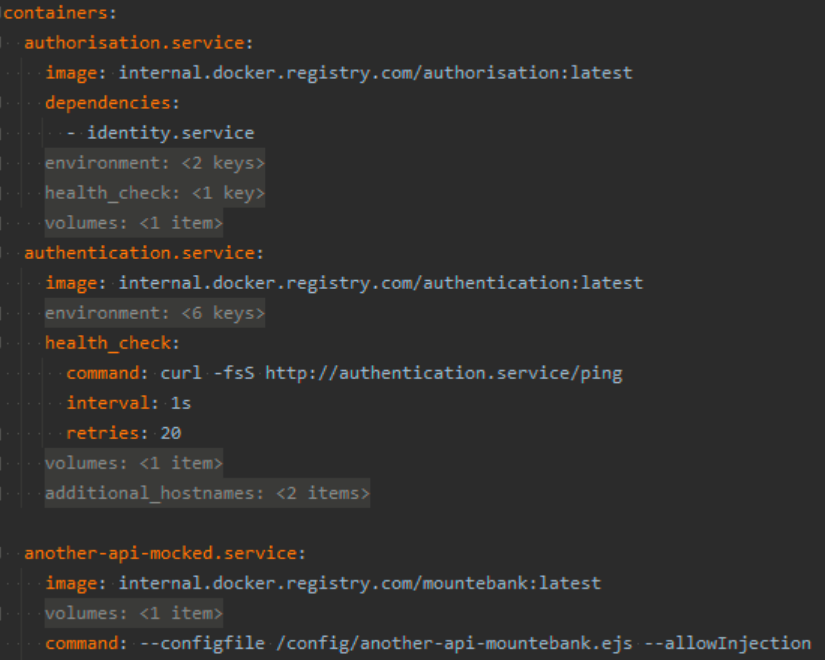
Batect container configuration
Batect is configured with Yaml. Here we define our containers which reference either a remote Docker image or local Dockerfile. The Yaml configuration is very similar to Docker Compose, and includes all of the features such as volume mounting and dependency resolution. In the file above you can see that the authorisation.service container depends on the authentication.service container. This means if we tried to bring up the authorisation container then Batect would automatically bring up the authentication container first, wait until it’s healthy, and then bring up the authorisation container.
For our most important API dependencies we use the exact Docker image which is deployed into production. For less important dependencies (or those which don’t run in Docker) which we mock them using Mountebank .
We then define the task which starts it

Batect task configuration
This gives us many advantages over a manual approach:
- All developers run the same version of each dependency. There’s no version drift across the team. Upgrades are made for everyone at the same time by changing the Batect configuration.
- Testing pre-release or potential upgrades of specific dependencies is easy; just a quick change to a Docker tag or
Dockerfile. - Easy developer onboarding. There’s no manual setup of local dependencies, it’s completely automated. Zero to Hello World is very quick.
- Immutable dependency stack. Services can be brought up and thrown away.
- Dependencies are defined as code. The project is explicit about exact versions of all dependencies.
Databases and State
Most applications operate on state and require a data store. One way around this is to mock these dependencies in local development however quality issues may arise as your local development setup drifts further away from the production environment.
An alternative is to use shared services such as stage environments but individuals making data and schema changes to the same data source leads to fragility. If the stage database is corrupted, brought down, or reset, then the entire team’s development workflow is blocked.
In my product we run a real SQL Server within a Docker container. The application and dependencies connect to this and source data like they would in production. An equal concern is managing production-like data for the application. We want to be developing against real world looking data, and how do we keep this in sync between all members of the development team?
We have a C# project called DataSeeder. This is a simple CLI application which connects to a SQL database and inserts it with a data set curated specifically for the app. The data is all defined in a simple C# DSL so stays version controlled with the project. In the Batect container configuration it depends on the database so is automatically run whenever the database is brought up.
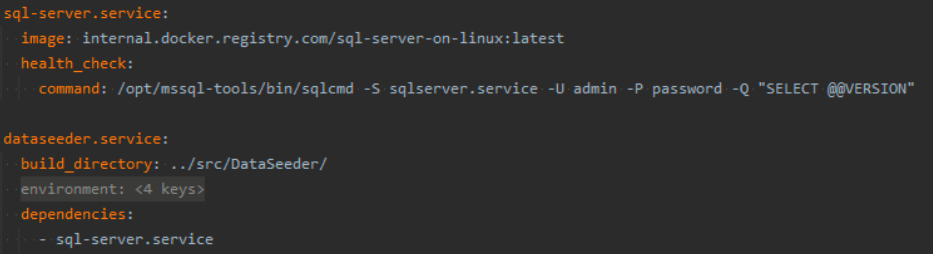
Batect database and dataseeder configuration
This gives us a version controlled data set specific to our application. Every developer works against a real world set of data. Not only do all dependencies stay in sync across the team, but the data we develop against does too. Developers are safe to make local changes to the database without fear of breaking anyone else’s workflow. When a change is ready then it can be committed back to master.
What I’ve described could be achieved with Batect or Docker Compose. In the rest of the article we’ll see what sets Batect apart.
Optimise for Developer Experience
Quality software is written on quality tooling. As Developers we have day to day tasks: running tests, linters, starting development servers, building documentation, and more. If these every day tasks are difficult, slow, or flakey then both the quality of the application and our enjoyment of working on it is going to suffer.
Alongside Containers, Tasks are a first class concept in Batect. Tasks are also defined in Yaml and are set to run inside one of the containers we’ve defined. We can compose across tasks and containers. For example, define several different tasks which run in the same container. Docker Compose has no concept of tasks, and writing your own ‘run several tasks against the same container stack’ mechanism leaves you with a bowl of cold soup.
In our job we’re often thinking about our customer’s user stories and journeys. As Developers what are our own ‘customer journeys’ that we carry out day to day?
One story is ‘I want to develop the API’. At the beginning of the blog we saw the task runDependencies. This starts all containers required to develop the API. Another story is ‘I want to run the API tests’. In practice this involves starting all dependencies and running an NUnit test project. It would be arduous and error prone to manually run these ourselves. With Batect’s task and container composition we can easily leverage the containers we’ve already declared to make it easier.
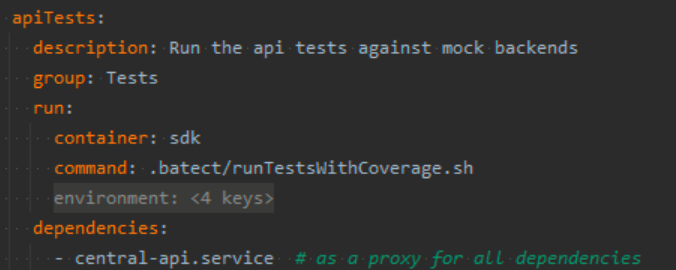
Batect APITest task configuration
Now when running ./batect apiTests Batect will spin up the dependency stack, wait until the containers are healthy, and then run the API tests. Once the tests finish running the stack is brought down.
Tasks run in Containers
What differentiates Batect from a task runner like Make is that Batect tasks run inside Docker containers. From a Developer Experience point this has a lot of upside. The day to day operations we carry out often run on different tech stacks. The application is written in C# so there are a bunch of .NET tasks such as running unit tests which run in the dotnet application container. Linting our Yaml source is done by the Python package yamllint, and we also have a process for locally compiling and validating the Kotlin build pipeline which requires Java and Maven.
We likely all have .NET installed on our workstations but what about the dependencies of other tasks? It’s a lot of unnecessary effort to configure Maven and keep Python packages up to date and synchronised across the team. Because Batect runs tasks in containers we specify, we get the two added benefits:
- Developers no longer need to install and configure the plethora of languages and libraries in order to develop the application. This makes onboarding new team members easy, and reduces the amount of documentation you need to maintain as a team.
- Tasks run the same across developer’s machines. My
./batect lintYamlruns the exact same as yours.
This underlines the key point that our common day to day tasks should be easy to carry out. Any friction on these, whether they are flakey, slow, hard to set up, or even just not being able to remember the command, means that quality of the application is going to suffer. If a Developer can reliably run anything - the linter, full end to end test suite, TC pipeline validation - by typing ./batect taskName then they’re going to do it.
What Should be a Task
The application I work on is made up of three git repositories, each use Batect. There’s the .NET Core BFF, the Typescript SPA, and a repository for Operations & Monitoring (New Relic Terraform). What should be defined as a Batect task? Any operation that runs in local development or in CI. For example in the BFF and SPA we have tasks for testing, linting, and building the respective repositories. In the Terraform app we have tasks for running Terraform plan and apply.
Simplify the Build Pipeline
TeamCity is the CI/CD software used at work. Complex CI software combined with a DSL (Kotlin) you rarely write makes it really easy to do the wrong thing. Build pipeline DSLs encourage coupling of the behaviour we want (running unit tests, a linter, terraform, etc..) to the source code of the pipeline. At first this is great, it allows us to rapidly develop the pipeline, however we soon find when build steps start failing we’ve designed a system that is difficult to debug. We want visibility into the pipeline, not for the system to be opaque. We can achieve this by having whatever runs in CI be able to run locally. This allows us to develop and debug the operations which are happening in the build pipeline.
Build pipelines go wrong when steps on the build server fail. If the failing step does not mutate system state (such as running unit tests or a linter) then we can try and reproduce the issue locally from our workstations. If the failing step does change the system in some way (modifying AWS resources, making a new Helm deployment) then we need to be much more careful.
.NET Test Example Here’s an example of a Kotlin build step which runs .NET tests for a project. Jetbrains encourage you to write your pipeline using steps like these. I’ll convince you it’s a bad idea, and show a better and even simpler way of writing pipelines using Batect tasks.
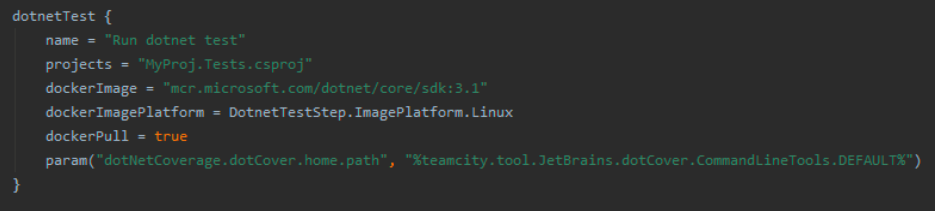
TeamCity Kotlin dotnetTest
This dotnetTest step has failed in CI however when you run the unit tests locally they pass. Where could it be going wrong? To start off with we’re not sure of the exact dotnet test ... shell command being run. We’d need to look in the build log. It’s likely the command being run has extra flags and options being passed to it. Do all Developers in the team use this exact command to unit test the project? Likely not. Already we’ve identified a difference between how we test in CI and test locally and perhaps a difference in how Developers test.
The second issue is around the Docker image. It’s great that the tests are being run in a Docker container; the software on build agents will be upgraded over time and we don’t want the software installed globally on build agents to impact the results of our steps. The downside here is that it’s awkward to replicate locally. We’d need to write our own Dockerfile which references the same image, copies our project source in, and runs the identical dotnet test ... command. Now there are two sources of truth for running unit tests: one for CI and one for local development.
Batect in Build Pipelines We move all implementation logic from the build pipeline into the Batect configuration.
From:
TeamCity Kotlin dotnetTest
To:
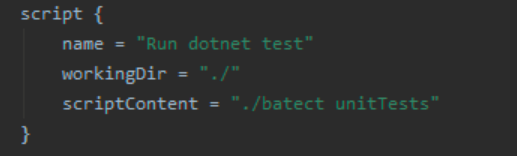
TeamCity script build step
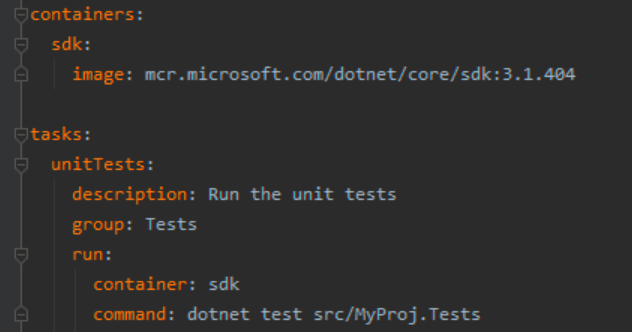
Batect container and task definition
This structure gives us a lot of advantages
- The build pipeline becomes simpler and easier to maintain. Platform specific DSL build steps are replaced by
scriptsteps. Your team no longer needs to learn deep behaviour of the CI platform DSLs because you’re no longer using platform specific steps. This makes the pipeline easy to maintain and upgrade over time. - Logic and complexity of each step is abstracted behind a Batect command. You can change the implementation of a step (ie. the specific dotnet test … command) without changing the name of the step or build pipeline source.
- Your team develops a clearer mental model of what is being run in the pipeline. If build steps call out to Batect commands, and the exact same Batect command can be run locally, then we learn what is going on.
- The operations in the pipeline become decoupled from the CI platform. Migrating between Jenkins, TeamCity, Github Actions, and CI platforms of the future becomes trivial as the actual functionality is encapsulated as Batect tasks.
By using the Batect we’ve aligned the operations in our CI pipeline to our everyday development work. We’ve developed a common language based on the name of the task. My team knows that running ./batect unitTests locally will run the unit tests in the exact same way on everyone else’s machine, as well as in CI.
Conclusion
Applying these three DevOps principles with Batect unlocks Continuous Deployment and Trunk Based Development. Previously integration and testing tasks were owned by the CI server with PR checks gatekeeping code. I’ve demonstrated that we can move all of this ’left’ to developers workstations unlocking faster feedback loops.
Delete your stage environment. By modelling all dependencies as Docker containers, and using the same Docker images which get deployed into production, you now have a prod-like environment which can be spun up anywhere. Developers don’t need to deploy to stage in order to check integrations between services, they can now validate this locally. Your test suite becomes much more reliable. This environment is now defined as code and can be developed and debugged locally. Your team saves time by no longer maintaining a stage environment.
Likewise with static analysis tasks which were previously the domain of PR checks. Our PR checks are now backed by Batect tasks so Developers can also run them locally. This allows true Trunk Based Development as we no longer need to open a Pull Request to validate every change. In turn this allows developers to work faster, work in smaller batches, and practice effective Pair Programming.
Batect tasks provide a common set of vocabulary for the development team. These also run the same everywhere. The build pipeline is also radically simplified as logic is moved out and into these task definitions. The build pipeline becomes easier to understand as build steps start mapping 1:1 with Batect tasks.
Get Started
Batect runs anywhere the JVM and Docker are installed. This includes nearly all build service build agents.
It’s really easy to get started with. Add it to your project, define a single task, and away you go. You don’t need to go ‘all in’ with Batect. Start off by defining some basic testing and linting tasks and get them running in CI. Over time you can add more tasks and start modelling additional dependencies.