Deploying code into production costs engineering teams. It’s not the dollar amount we care about but the time and attention engineers have to spend on the deployment. Projects with a complex release process, slow pipelines, or flakey steps are expensive to deploy. This cost feeds back into how we work and has detrimental effects on how we write code, work as a team, and run systems as professionals.
A Zero-cost Deployment is completely automated. Engineers are confident in the correctness of the code, the comprehensiveness and consistency of the test suite, the reliability of the deployment pipeline, and the quality of monitoring and alerting that runs in production. With true Zero-cost Deployments engineers don’t even need to be aware a deployment is happening. This is our goal.
Zero-cost Deployments in Practice
At work my team practices Continuous Deployment and Trunk Based Development. Zero-cost Deployments are a key factor in the Continuous Delivery way of working and enable us to deliver value faster to our customers.
We do a lot of Mob and Pair Programming. Writing code this way is great. We discuss, learn, and share knowledge of our code base and product in realtime. This is not only lots of fun, but it builds resiliency in the team by sharing knowledge - a lot more than would be typically shared in a code review of a pull request. We co-author commits to meet internal engineering standards, run any appropriate tests locally, and then commit to master and push to origin.
When a commit lands in master a deployment to production is automatically started. Fifteen minutes later the code has been through the pipeline and is in front of customers in production. We use TeamCity with the the Kotlin DSL but the CI/CD software does not matter. Whatever you use I recommend keeping most logic out of the pipeline DSL and within Docker containers. See DevOps Practices for Continuous Deployment
.
When a deployment begins a thread is created in the team’s releases Slack channel. As the deployment progresses the thread gets updated with success/failure indicators. If a step fails then the person who authored the commit gets pinged on Slack. If everything is successful then no one gets interrupted. We’re confident that we’ll be notified if something goes wrong so we don’t even need to be notified when a deployment begins or successfully finishes.
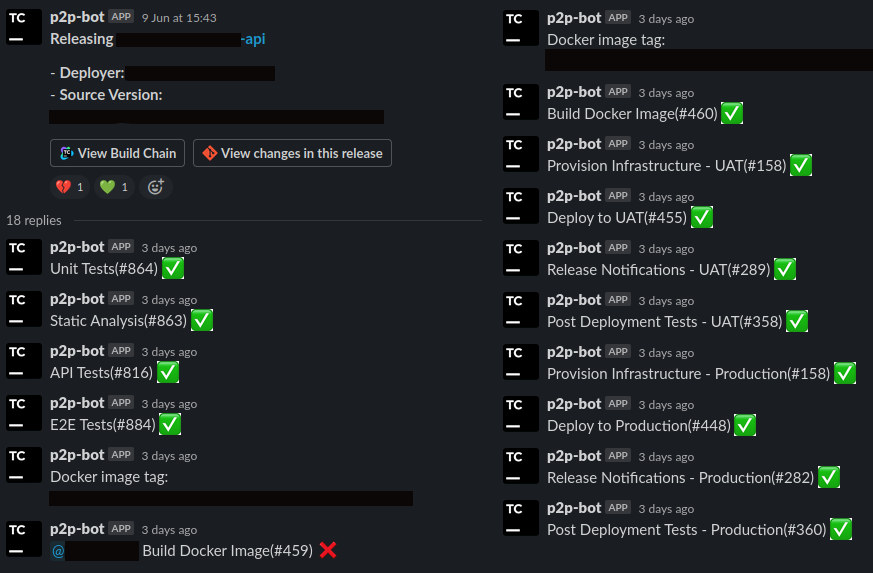
ChatOps in action. An example of a failing build step tagging the deployer.
In addition to the automated tests, pre-prod smoke test, and prod smoke test within the deployment pipeline a New Relic Synthetic Monitor is constantly running on our production environment verifying our most common user story. This acts as a last resort to pick up change failures and notifies the team immediately if a broken build got into production.
Why Do Zero-cost Deployments
Everything in DevOps is feedback loops and code deployments are no different. Here are some positive impacts I’ve seen on my team.
Improve Quality of the Application. Zero-cost Deployments require teams to have complete trust in their test suite and build pipeline. Signs you don’t have this are manually checking the production environment after a deployment or watching the build as it progresses through a deployment. When a deployment pipeline has flakey steps and is in a bad state the marginal cost of another part of the pipeline turning flakey is small; you already have to watch the entire deployment pipeline, it’s no additional hassle to re-run another step. It’s Broken Windows Theory for the pipeline. With Zero-cost Deployments any step turning flakey has a huge marginal cost on the team and there is large incentive to immediately fix it. By getting your pipeline to a state of Zero-cost Deployment you enter into a feedback loop which keeps test quality and pipeline reliability high.
Engineers Get Time Back. Deployments happen continuously in the background. Engineers no longer need to even open the build pipeline so get hours of their week back. Cognitive load is reduced as it’s un-necessary need to follow a release process or operate the CI/CD software in such detail.
Incentivises Trunk Based Development. Zero-cost Deployments feeds back into how we write code. With deployments being free we’re incentivised to write small commits and immediately deploy them into production. Small change sets reduce the change failure rate and improve the availability of the application. Zero-cost Deployments make feature branches and deployments of several commits seem like an anti-pattern.
General Happiness at Work. Slow and unreliable deployments cause friction in the team. Rarely personal, but more generally at the systems themselves which shows in people being reluctant to deploy. With Zero-cost Deployments this doesn’t exist. Deployments are a non-issue and engineers are eager to get the code they wrote into production as soon as they can.
Steps Towards Zero-cost Deployments
You have an existing deployment pipeline which requires time and attention to operate. You’re wanting to improve it. Where do you start? Gather the team and map out the pipeline. Of interest are:
- Steps which require manual intervention. These require the attention of the deployer and may point to dependencies on other systems.
- Steps which require coordination. Includes requiring permission to begin a deployment or someone to sign off that tests have passed.
- Steps which are flakey. Even if they fail 1% of the time, highlight them. This could point towards tests which need to be improved or removed, or reliance on third party systems which need to be addressed.
Also consider:
- The release of new features to customers. In many products feature release are timed with marketing announcements or may be released with a gradual rollout. We are seeking Zero Cost Deployments and the ability to deploy at any time. The release of features should be controlled with feature flags.
- Git practices. The use of long lived feature branches indicate some additional requirement. Perhaps feature branches are deployed to staging environments to test new features. Are there alternatives?
- Are deployments often paused? Dig into why.
- Trust in the test suite. Once code has been deployed to production or pre-prod do engineers open the newly deployed system to check that it works? This highlights a lack of trust in the test suite.
- Trust in monitoring. Likewise checking the newly deployed system for hours after a deployment indicates lack of trust that the monitoring system will detect and alert them to a defect.
- The build is always broken. Code gets merged into
masterbranch but it fails Continuous Integration checks. This points to improvements in tests, static analysis, or team process. - Deployments take a long time to complete. Every system has its quirks and testing requirements which can’t be unpacked in a general article like this. That being said if a deployment takes longer than 30 minutes then there is likely potential for improvement. Can build agent resources be increased to make steps run faster? Can build steps be parallelised? Can slow testing frameworks be swapped out for faster ones?
- Can automated testing steps of the pipeline be run on a local workstation? Shift left on quality and enable thorough automated testing to be run before code even touches the pipeline.
These insights must come from the whole team. Individuals will know different quirks about the deployment pipeline. Talking to select engineers or looking at aggregated build metrics will not provide the context required in order to make meaningful improvement.
Conclusion
Zero-cost Deployments are a game changer for engineering teams. The time they would otherwise spend deploying code is now given back to them. Quality of the application improves and teams gain resiliency by pairing and mobbing where they otherwise wouldn’t. Feature releases become completely de-coupled from code deployments and other aspects of Continuous Delivery can be focused on. It works astronomically well for my team and is a quality we strive to keep.