In 1968 a group of computer scientists gathered in Garmisch, Germany for what became known as the NATO Software Engineering Conference. The conference was themed around the apparent software crisis: the world is becoming more reliant on software, yet software systems are getting larger, miss deadlines, go over budget, and are brittle to change. The attendees gathered to discuss this, the factors that contribute to this reality, and propose ways to align the creation of software to the engineering discipline.
The Garmisch conference produced a 100 page report titled Software Engineering . The report, edited by Brian Randell and Peter Naur, is a collection of conversations, quotes and paper extracts from the conference. In this post I share extracts from the report coupled with my own understanding of the context of software in 1968. I highlight the ideas that are both eerily similar and radically different from the realities we face in software systems today.
Setting the Scene
It’s 1968 and there are 10,000 computers in Europe. This number is set to double every year. A group of 40 academics gather for the Garmisch conference. NATO sponsors it so they send a few people along to listen and learn.

Photograph from the conference.
Some of the names we may recognise today are Edsger Dijkstra, CAR Hoare, Alan Perlis, Peter Naur, and Niklaus Wirth. The attendees are largely from a scientific background, and rotate between industry jobs and academia. They typically work on systems such as operating systems, compilers, and programming languages.
The ‘software gap’ (at other times called the ‘software crisis’) is summarised as follows:
The basic problem is that certain classes of systems are placing demands on us which are beyond our capabilities and our theories and methods of design and production at this time. There are many areas where there is no such thing as a crisis — sort routines, payroll applications, for example. It is large systems that are encountering great difficulties. We should not expect the production of such systems to be easy.
Kenneth Kolence - Software Engineering (1968) pg 71
It’s not just that software is becoming more complex, it’s that computer systems are playing a greater role in society. In 1968 computers were used for data processing at large companies and institutions. Personal computers weren’t yet available.
Software
In the 1960s the term Software referred to the tools used to construct other programs: operating systems, compilers, and programming languages. Everything that ran on top of software such as payroll systems and calculators were applications. Thomas Haigh’s Software in the 1960s as concept, service, and product provides a view into that world.
Conference attendee d’Agapeyeff presents this model as the stack that applications run on. He describes it as “very sensitive to weaknesses in the software”
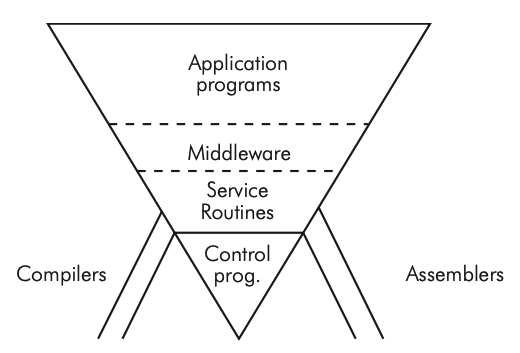
d'Agapeyeff's inverted pyramid model.
This sensitivity of software can be understood if we liken it to what I will call the inverted pyramid. The buttresses are assemblers and compilers. They don’t help to maintain the thing, but if they fail you have a skew. At the bottom are the control programs, then the various service routines. Further up we have what I call middleware.
This is because no matter how good the manufacturer’s software for items like file handling it is just not suitable; it’s either inefficient or inappropriate. We usually have to rewrite the file handling processes, the initial message analysis and above all the real-time schedulers, because in this type of situation the application programs interact and the manufacturers, software tends to throw them off at the drop of a hat, which is somewhat embarrassing. On the top you have a whole chain of application programs.
The point about this pyramid is that it is terribly sensitive to change in the underlying software such that the new version does not contain the old as a subset. It becomes very expensive to maintain these systems and to extend them while keeping them live.
d’Adapeyeff - Software Engineering (1968) pg 14
Today’s abstraction of hardware, operating systems, and applications was also different. Hardware manufacturers bundled the operating system with the hardware they were selling. Multi target compilers such as GCC and LLVM did not exist, nor interpreted languages that support the combinations of different operating systems and hardware such as Python and NodeJS. Mainframe systems would have different memory layouts and processors so software had to be written for a particular mainframe. Write once, run anywhere wasn’t even a joke.
Software such as compilers and schedulers, already coupled to a mainframe, had to abstract over the mainframe’s system APIs in order to remove faults. Applications could then be built using these compilers. Leaky abstractions are a reality, and so applications being built were forced to consider the mainframe operating system, compiler, and quirks of the combination of the two.
The scope of this conference is not large enough … We should start by designing hardware and software together. This will require a kind of general-purpose person, a ‘computer engineer’.
Barton - Software Engineering (1968) pg 21
This problem of fragile software and applications due to underlying hardware and operating system quality has been largely solved today through abstraction. We can write high level Python code which operates on files and be reasonably confident that it will run consistently wherever Python can. Indeed conference attendee Babcock saw this future.
The future of new operating system developments in the future may depend more and more on new hardware just on the horizon. The advent of slow-write, read-only stores makes it possible for the software designer to depend on a viable machine that has flexible characteristics as opposed to rigid operation structures found in most of today’s machines. If the software designer had access to a microprogramming high-level language compiler, then systems could be designed to the specific problem area without severe hardware constraints. Major U. S. manufacturers including IBM, UNIVAC, Standard Computer, RCA are building or seriously considering such enhancements.
Babcock - Software Engineering (1968) pg 21
Today we still need to know about the hardware our code will run on. There’s a lot of variation between systems: Compute resource allocation for our services, IO characteristics for read/write heavy workloads, and in the case of software consumed by customers we need to know what hardware they’re using: phones, tablets, screen sizes, keyboards, etc.
The largest and most problematic hardware issue most software engineers face today are networks. Not something the attendees of the Garmisch needed to wrestle with. We can think of networks introducing a couple of categories of complexity.
The first is the unreliability and variability that happens within the various layers of the network stack (think latency and routing). We write defensive code to be resilient to network faults and incur the cost of complex code as we move operations to asynchronous and retryable workflows. There’s also a category of undefined behaviour of our systems when critical dependencies go down, or worse slow down. For example if the authentication server goes down then the application doesn’t work. If the authentication server responds at 100x the median response rate what happens?
The second is fundamental to what networks allow us to construct. Systems can now span many computers and APIs. The systems talked about in 1968 ran only on a single machine. Even then the attendees talk about how sensitive and fragile the software system is. Today an HTTP request to a reasonably large SaaS product may cause a ripple on tens or hundreds of machines. How would we compare the fragility of software systems today to those of 54 years ago?
Software Engineering
The editors of the report give us insight to the phrase software engineering:
The phrase ‘software engineering’ was deliberately chosen as being provocative, in implying the need for software manufacture to be based on the types of theoretical foundations and practical disciplines that are traditional in the established branches of engineering.
Editors - Software Engineering (1968) pg
This is something we still aspire to today. When we fly on a plane we wish that the software that flies it was developed through an engineering rather than artistic methodology. The report attendees discussed two ways to get there: the industrialisation of software, and formal mathematics.
M.D McIlroy presents Mass Produced Software Components at the Garmisch Conference. The entire paper is worth a read. Abstract below:
Software components (routines), to be widely applicable to different machines and users, should be available in families arranged according to precision, robustness, generality and timespace performance. Existing sources of components — manufacturers, software houses, users’ groups and algorithm collections — lack the breadth of interest or coherence of purpose to assemble more than one or two members of such families, yet software production in the large would be enormously helped by the availability of spectra of high quality routines, quite as mechanical design is abetted by the existence of families of structural shapes, screws or resistors.
McIlroy - Software Engineering (1968) pg 79
He makes the case that we should view the creation of software through the lens of mass production.
When we undertake to write a compiler, we begin by saying ‘What table mechanism shall we build?’ Not, ‘What mechanism shall we use? but ‘What mechanism shall we build? I claim we have done enough of this to start taking such things off the shelf.
McIlroy - Software Engineering (1968) pg 80
In today’s context we have open source programming languages and systems with well supported ecosystems. In terms of technology choices, open source has got us some of the way to ‘which mechanism shall we use?’ Engineers pick common databases, web frameworks, and libraries. Though from that starting point we’re quite happy to change the frame back to ‘which mechanism shall we build?’
Programming started from mathematical roots and the call for the formalisation of systems continues on to today.
There is no theory which enables us to calculate limits on the size, performance, or complexity of software. There is, in many instances, no way even to specify in a logically tight way what the software product is supposed to do or how it is supposed to do it. We can wish that we had the equivalent of Shannon’s information theorems, which tell how much information can be transmitted over a channel of given bandwidth and given signal-to-noise ratio, or Winograd’s theorem specifying the minimum addition time, given the switching and delay times in the basic circuitry, but we don’t have such existence limits for software.
David - Software Engineering (1968) pg 39
The thing with correctness is that you either have it or you don’t. Today we don’t, but useful mechanisms such as more advanced types systems are creeping into mainstream languages. Type systems provide some level of safety, but a greater benefit to the programmer to help them understand the code base.
Gillette and Perlis continue the tradition of John Wilkins and Leibniz. Shortcomings are the result of not having a formal language.
One type of error we have to contend with is inconsistency of specifications. I think it is probably impossible to specify a system completely free of ambiguities, certainly so if we use a natural language, such as English. If we had decent specification languages, which were non-ambiguous, perhaps this source of error could be avoided.
Gillette - Software Engineering (1968) pg 35
Perlis refines this:
However, there is another reason why people don’t do predocumentation: They don’t have a good language for it since we have no way of writing predicates describing the state of a computation.
Perlis - Software Engineering (1968) pg 35
Software is Designed and Produced
Software was first designed, then the plans were handed over to designers to produce the software according to the specification (write the code). We know this doesn’t work today, and the attendees at Garmisch also highlighted the same reasons why. What’s curious is that they seem to want software to be designable before any code is written.
First a quote from Naur. Emphasis mine.
Software production takes us from the result of the design to the program to be executed in the computer. The distinction between design and production is essentially a practical one, imposed by the need for a division of the labor. In fact, there is no essential difference between design and production, since even the production will include decisions which will influence the performance of the software system, and thus properly belong in the design phase. For the distinction to be useful, the design work is charged with the specific responsibility that it is pursued to a level of detail where the decisions remaining to be made during production are known to be insignificant to the performance of the system.
Naur - Software Engineering (1968) pg 20
The middle of the quote talks about there is no difference between design and production. Design is continuously evolving, and during implementation the writers of software discover new things and need to make decisions on the fly. That’s the same reality we see today. But the two sections I emphasised hint that there needs to be a designer.
Likewise this quote from Dijkstra.
Honestly, I cannot see how these activities [Design, Production] allow a rigid separation if we are going to do a decent job. If you have your production group, it must produce something, but the thing to be produced has to be correct, has to be good. However, I am convinced that the quality of the product can never be established afterwards. Whether the correctness of a piece of software can be guaranteed or not depends greatly on the structure of the thing made. This means that the ability to convince users, or yourself, that the product is good, is closely intertwined with the design process itself.
Dijkstra - Software Engineering (1968) pg 20
I get the impression that the attendees understood that the design couldn’t be done up front, but that if the software was written according to the eventually evolved design then the software would work as intended. Perhaps this was due to the nature of the systems they worked on – compilers and other systems programming with very formal correctness criteria. I think of products and SaaS I’ve worked on where indeed the software was written according to the design, but the eventual behaviour of how the software should be used was completely emergent. It’s like the organisation puts together a collection of microservices and user interfaces, each of which are verified and tested independently and in specific combinations. But the operation and behaviour of the system as a whole is completely defined by the customer. They know where the buggy screens are, they know they need to configure a record in a specific way before submitting it, etc.
An unsolved problem in Software Engineering today is how we can resolve and align internal and external designs and documentation. Complex systems typically have hundreds of pages of customer documentation describing how the system works and what actions they need to take to get the outcome they want. Behind this singular SaaS presented to the customer are hundreds of microservices, databases, and workers. These all come with code-level architecture, design, and documentation. In practice the external documentation defines the actual behaviour of the system. But when a programmer is working at the code level how can they be presented with the relevant set of data they need to make a decision? It’s like we need forever up to date links and connections between internal and external documentation. Kolence presents this:
Another area of difficulty which faces the designer of a program is how to relate the descriptions of the external and internal designs. The notation of external characteristics tends to be narrative and tabular, whereas internal design notation normally consists of flow charts and statements about key internal containers and tables. An external set of characteristics which is appropriately cross-referenced to the internal design, and which clearly illustrates the impact of features or sets of features on the internal design would be of great value to both the designer and the manager.
Kolence - Software Engineering (1968) pg 34
Is this solvable through technology? (probably not).
A standard for program documentation when programs are written in symbolic machine language should be set and each program should include this standard documentation in the ‘remarks field’ of the symbolic program.
This documentation should include sufficient information and in such a way that a computer program can flow trace any program according to specified conditions.
Then a computer program can be used to assist in evaluating and checking the progress of the program design. Computer studies of the realtime used under varying conditions can be made and studies to see that memory interfaces are satisfied can be made.
Harr - Software Engineering (1968) pg 52
The Scale of Software Systems
Attendees saw the ever increasing scale of software being a problem. Both from the count of lines of code, as well as the number of people required to work on a single system.
In the context of the apparent ‘software crisis’ graphs such as below are intimidating.
Production of large software has become a scare item for management. By reputation it is often an unprofitable morass, costly and unending. This reputation is perhaps deserved. No less a person than T. J. Watson said that OS/360 cost IBM over 50 million dollars a year during its preparation, and at least 5000 man-years’ investment. TSS/360 is said to be in the 1000 man-year category. It has been said, too, that development costs for software equal the development costs for hardware in establishing a new machine line.
David - Software Engineering (1968) pg 37
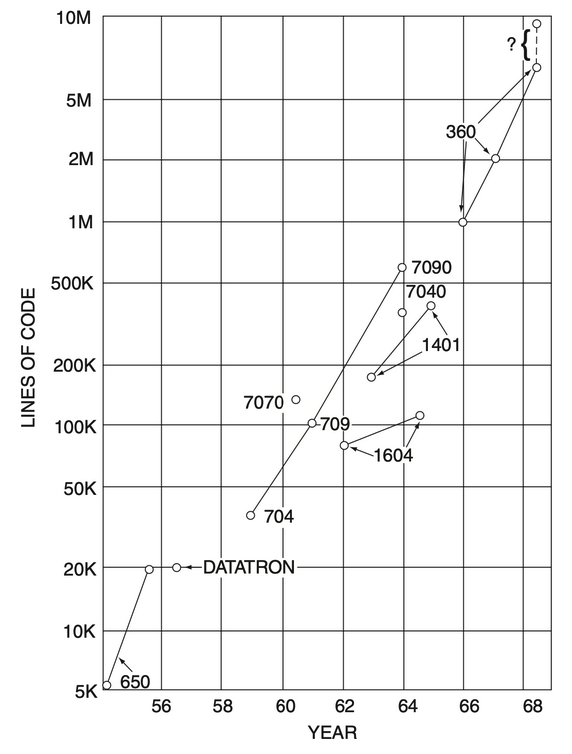
Lines of code in Mainframe systems.
I am concerned about the current growth of systems, and what I expect is probably an exponential growth of errors. Should we have systems of this size and complexity? Is it the manufacturer’s fault for producing them or the user’s for demanding them? One shouldn’t ask for large systems and then complain about their largeness.
Opler - Software Engineering (1968) pg 61
I underline that the software systems they are talking about run on a single machine. This is before networked systems were widely used! Today the majority of systems are distributed systems. The subsystems which make up the whole communicate using APIs and protocols. Subsystems can be developed by smaller teams, reducing cost to coordinate at the code level (the DevOps “small autonomous team”). Subsystems can also be deployed and scaled separately, allowing compute and storage resources to be right sized to the workload. Even though the paradigm of software systems has shifted, many of the comments from the 1968 conference are still relevant.
The good systems that are presently working were written by small groups. More than twenty programmers working on a project is usually disastrous.
Buxton - Software Engineering (1968) pg 39
At a subsystem level, this is debatably true today. And yet Perlis’ argument below for why software must scale applies at the larger system level.
We kid ourselves if we believe that software systems can only be designed and built by a small number of people. If we adopt that view this subject will remain precisely as it is today, and will ultimately die. We must learn how to build software systems with hundreds, possibly thousands of people. It is not going to be easy, but it is quite clear that when one deals with a system beyond a certain level of complexity, e.g. IBM’s TSS/360, regardless of whether well designed or poorly designed, its size grows, and the sequence of changes that one wishes to make on it can be implemented in any reasonable way only by a large body of people, each of whom does a mole’s job.
Perlis - Software Engineering (1968) pg 39
Planning and Estimates
Commentary on the difficulty of planning, and apparent impossibility of estimating software projects hasn’t changed in the last 54 years. I highlight this to contrast to the earlier quotes around Software Design. Compared to today, there was more effort put in the upfront design and a want (if not belief) that the design could be ‘correct’. That considered, estimates were not remotely accurate.
Computing has one property, unique I think, that seriously aggravates the uncertainties associated with soft- ware efforts. In computing, the research, development, and production phases are often telescoped into one process. In the competitive rush to make available the latest techniques, such as on-line consoles served by time- shared computers, we strive to take great forward leaps across gulfs of unknown width and depth. In the cold light of day, we know that a step-by-step approach separating research and development from production is less risky and more likely to be successful. Experience indeed indicates that for software tasks similar to previous ones, estimates are accurate to within 10–30% in many cases. This situation is familiar in all fields lacking a firm theoretical base. Thus, there are good reasons why software tasks that include novel concepts involve not only uncalculated but also uncalculable risks.
David - Software Engineering (1968) pg 41
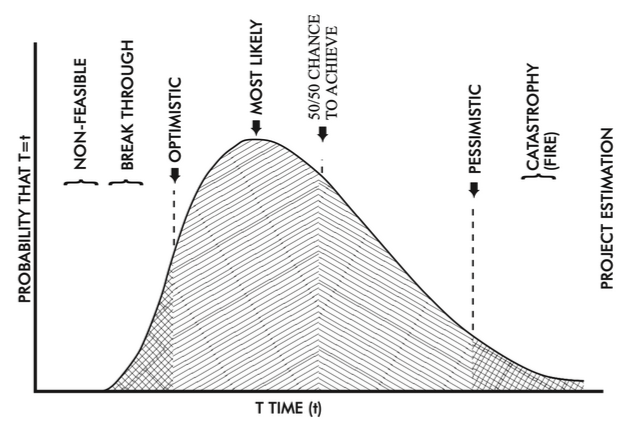
Nash Illustrating Projects Estimate vs Actual Time
They likewise highlight sometimes who is doing the job is often a better indicator than the complexity or size of the job. Something we seem to forget today.
I would never dare to quote on a project unless I knew the people who were to be involved.
Fraser - Software Engineering (1968) pg 50
Engineering Metrics
In my day job I lead development of an Engineering Metrics application. While not a section of the Garmisch Report, I’ve selected a few quotes.
One of the problems that is central to the software production process is to identify the nature of progress and to find some way of measuring it. Only one thing seems to be clear just now. It is that program construction is not always a simple progression in which each act of assembly represents a distinct forward step and that the final product can be described simply as the sum of many sub-assemblies.
Fraser - Software Engineering (1968) pg 51
In modern metrics lingo we know that ‘output metrics’ are next to useless. These are metrics such as lines of code, number of commits, and number of pull requests. These metrics tell us that code has been added to the system, but due to the nature of software systems we don’t know if it delivered value, got the system any closer to completion, or added a bug.
I know of one organisation that attempts to apply time and motion standards to the output of programmers. They judge a programmer by the amount of code he produces. This is guaranteed to produce insipid code — code which does the right thing but which is twice as long as necessary.
McClure - Software Engineering (1968) pg 52
This model of Software Design and Software Production comes into play here. If the Design describes exactly what needs to be built, then we can measure progress by the programmers checking parts off as they implement it.
Each program designer’s work should be scheduled and bench marks established along the way so that the progress of both of his documentation and programs can be monitored. (Here we need a yardstick for measuring a programmer’s progress other than just program words written.) The yardstick should measure both what has been designed and how, from the standpoint of meeting the design requirements. Programmers should be required to flowchart and describe their programs as they are developed, in a standard way. The bench marks for gauging the progress of the work should be a measure of both the documents and program produced in a given amount of time.
Harr - Software Engineering (1968) pg 52
On milestones.
The main interest of management is in knowing what progress has been made towards reaching the final goal of the project. The difficulty is to identify observable events which mark this progress.
Kolence - Software Engineering (1968) pg 52
Things That Haven’t Changed in 54 Years
Measuring progress on the construction of a system.
One of the problems that is central to the software production process is to identify the nature of progress and to find some way of measuring it. Only one thing seems to be clear just now. It is that program construction is not always a simple progression in which each act of assembly represents a distinct forward step and that the final product can be described simply as the sum of many sub-assemblies.
Fraser - Software Engineering (1968) pg 10
Lean Software Development.
Define a subset of the system which is small enough to bring to an operational state … then build on that subsystem. This strategy requires that the system be designed in modules which can be realized, tested, and modified independently.
David - Software Engineering (1968) pg 24
Resilience Engineering.
I just want to make the point that reliability really is a design issue, in the sense that unless you are conscious of the need for reliability throughout the design, you might as well give up.
Fraser - Software Engineering (1968) pg 26
Engineers must be equipped with the right tools to do the job.
A reliable, working system incorporating advanced programming and debugging tools must be available from the beginning. One requirement is an accessible file system for storing system modules and prototypes. An adequate file system should act as a common work space for system programmers and should have back-up facilities to insure against loss of valuable records.
David - Software Engineering (1968) pg 55
Conclusion
Reading the report about the 1968 NATO Conference was fascinating. Some of the ideas and problems are identical to what we talk about at the coffee machine today. Other problems we can only dream of, having been solved in the layers of abstraction of systems we build upon.
I’ve presented only a fraction of what is talked about in the report. If any of this interests you then check out the report and other material in the links below.
References
- NATO Software Engineering Report 1968 - Peter Naur and Brian Randell.
- Software in the 1960s as Concept, Service, and Product - Thomas Haigh.
- Crisis, What Crisis? - Thomas Haigh.
- The Roots of Software Engineering - Michael S Mahoney.
- 2001 interview with Kenneth Kolence - Jeffrey Yost.