In this blog I share my experience in building a Python REPL augmented with ChatGPT. I explore how the application is built, and speculate on software engineering patterns and paradigms that might emerge in systems built on Large Language Models (LLMs).
GEPL - Generate, Evaluate, Print, Loop
Introduction
The Lisp programming language made REPLs (Read, Evaluate, Print, Loop) famous. REPLs are interactive programming environments where the programmer gets immediate feedback on lines of code they just typed. Today REPLs are common in Python, F#, and nearly every mainstream language.
While using ChatGPT through the OpenAI website I noticed parallels to a REPL. Both setup ongoing dialogues between a user and their computer system. The concept of REPL and ChatGPT sessions is that a single idea or concept can be declared and then refined until it works. The key feature is that the context of the conversation is preserved within a session. For REPLs this means symbols, state, and functions. For ChatGPT, it’s the thread of discussion.

ChatGPT - conversations have context.
I wanted to explore how these two technologies could augment each other. I did this by creating GEPL - Generate, Evaluate, Print Loop. It has the normal functionality of a Python REPL, you can type lines of code and execute them in the session. It also allows you to prompt the ChatGPT API to generate code for you. The ChatGPT prompt has context of code you’ve entered locally, so you can ask it to generate new code, or modify code you’ve written.
GEPL
Behind the scenes it uses the Python framework LangChain and OpenAI’s ChatGPT. However the code isn’t coupled to OpenAI’s implementation, and can be swapped out for other Chat Model LLMs as they’re released.
Architecture
GEPL’s architecture unifies the state between a Python interpreter and a ChatGPT conversation. This enables ChatGPT to manipulate and design its answers around we’ve written locally.
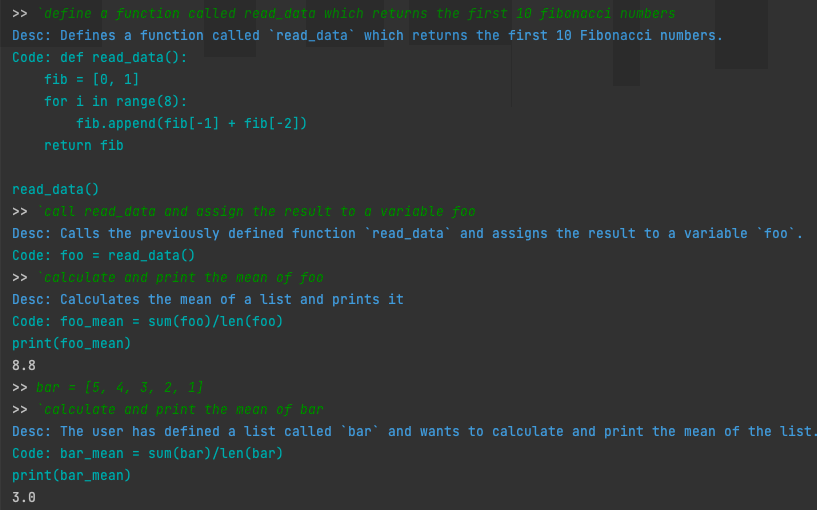
GEPL can modify code you've declared locally
GPT-3, GPT-4, and other APIs wouldn’t work because there’s no way to carry context across multiple prompts within a session. The type signature for those APIs are str -> str, they are essentially functions which take in a string (the prompt) and return another string (the answer).
Chat Model APIs are also technically stateless in that every request is independent, however the API could be modelled as List[Message] -> str, where it takes a list of messages and returns some answer. These messages can be one of two types:
SystemMessage- Messages from GEPL instructing ChatGPT how to behave.HumanMessage- Messages from the user prompting ChatGPT to respond.
We’ll get into the details on the prompts of the messages below, but to grasp the magic of how this architecture works we need to understand that:
- GEPL maintains a local state of every command that has been typed into it and the result of execution.
- Every time ChatGPT is called this historical state is passed as a list of
SystemMessage. - The current prompt is sent as a
HumanMessage.
This allows ChatGPT to operate on code that either it or the user has written. Chat Model APIs are still very new and OpenAI’s ChatGPT is currently the only implementation. If you’re interested in more about the Chat Model API and how it differs to the other LLM APIs (eg. GPT-3, GPT-4) then read the Chat Models LangChain blog .
Prompts
Sometimes we want ChatGPT to generate some Python code. Other times we just want to tell it what has been executed in the REPL so that it maintains the state of the session. How do we do this? There’s nothing intrinsic in ChatGPT that it knows it’s a Python REPL. LLMs aren’t programmed through an API or configuration, they’re programmed through natural language called prompts. Prompts are equal parts powerful and fragile. What they allow us to do is amazing, but from an engineering and reliability point of view they can trip us up.
GEPL has four types of prompts :
- Initial Prompt – A one off SystemMessage to bootstrap the conversation.
- Prompt for Code Generation - HumanMessage where the user prompts the LLM to write code.
- Generated Code Executed Prompt - SystemMessage passed back to the LLM to record execution of code it has generated.
- User Code Executed Prompt - SystemMessage passed back to the LLM to record execution of code the user wrote.
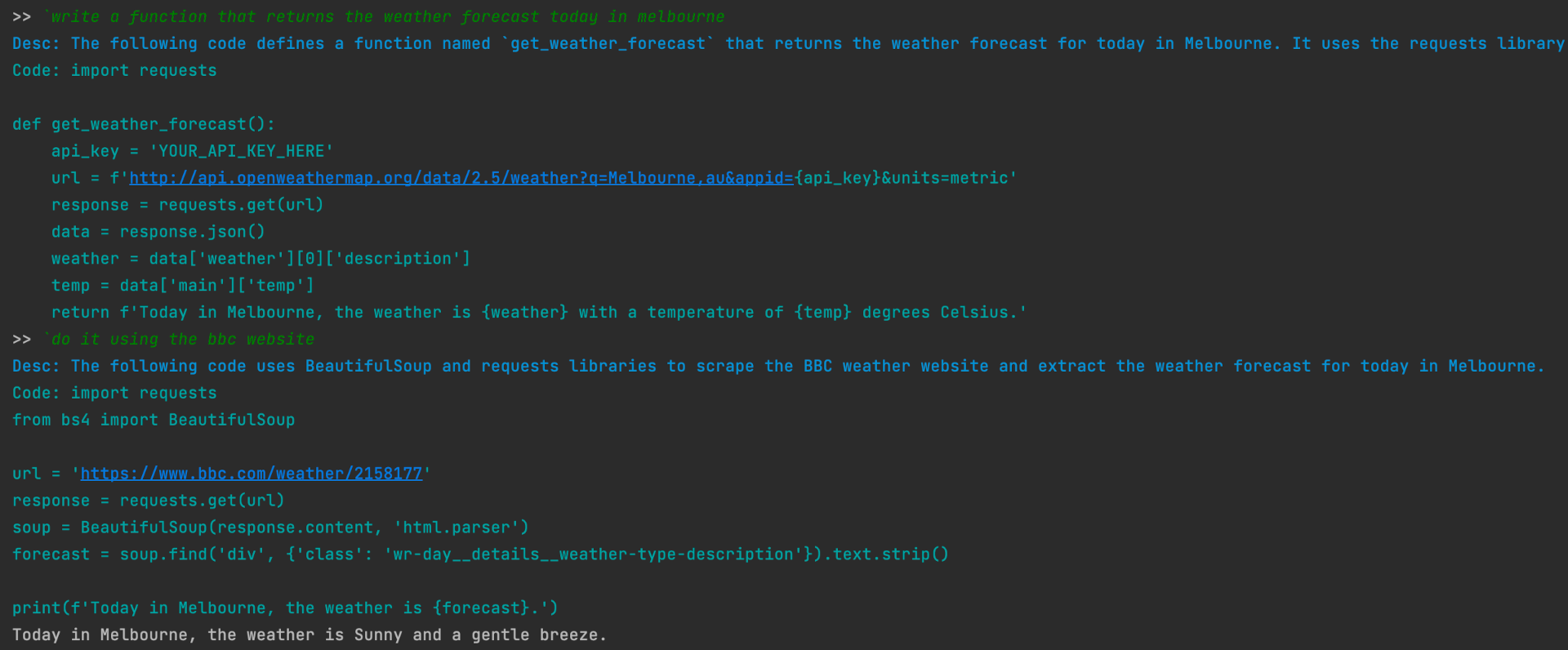
Input and code execution add prompts to the stack.
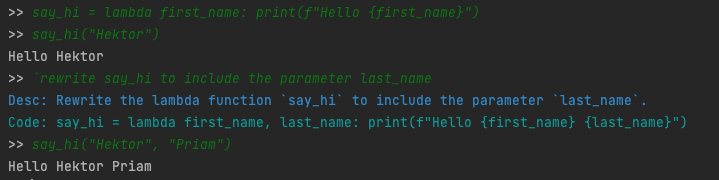
For this simple example, at the time of say_hi("Hektor", "Priam") the prompt stack is as follows:
- Initial Prompt Message
- User Code Executed Prompt:
say_hi = lambda first_name: print(f"Hello {first_name}") - User Code Executed Prompt:
say_hi("Hektor") - Prompt for Code Generation:
`rewrite say_hi to include the parameter last_name - Generated Code Execute Prompt: For when the above line was executed.
Without these prompts ChatGPT would not know the state of code that either it or the user wrote, nor the symbols and side effects that are present in the GEPL. Now we’ll look at the four prompts in detail.
Initial Prompt
Whenever GEPL calls the ChatGPT API, this is the first message it sees.
You are a python code generator. Write well-written python 3 code.
The code you generate will be fed into a REPL. Some code and symbols may already be defined by the user.
If you cannot return executable python code return set the reason why in the description and return no code.
If you generate a function do not call it.
Return executable python3 code and a description of what the code does in the format:
STARTDESC description ENDDESC
STARTCODE code ENDCODE
Some of those words look superfluous, some look bizarre, but every single one is required. These instruct the LLM …
- What it is (a code generator), what the code it generates will be used for, and that it should write well-written code.
- What to do if it can’t generate the code. This acts as permission for it to ‘give up’ on a task, rather than hallucinate some answer that makes no sense.
- The format in which it should reply. Without this the
strreturned by the API would be on one of four formats – with code blocks and text blocks in different locations making it a challenge to parse.
Prompt for Code Generation
This prompt is always the last in the list of Messages passed to the ChatGPT API. It’s a direct pass through of what the user entered into the GEPL. eg.
rewrite say_hi to include the parameter last_name
Generated Code Executed Prompt
This SystemMessage records code that has been generated and the result of execution. It has the following prompt template.
Previously the user asked you {message} and you generated code
{code}
Do not run this code again.
This code was evaluated in a python3 interpreter and returned
{result}
Where the bracketed parameters are substituted in. From the example above, once the line has been executed, the SystemMessage will be appended to the prompt stack and passed to the next call to the ChatGPT API with the following parameters.
- message =
rewrite say_hi to include the parameter last_name - code =
say_hi = lambda first_name, last_name: print(f"Hello {first_name} {last_name}") - result =
None– as a function was defined.
This template approach is implemented using LangChain’s PromptTemplate abstraction.
User Code Executed Prompt
This SystemMessage records code that the user wrote and the result of execution. It has the following prompt template.
The user has executed code.
This is the code that was executed:
{code}
Do not run this code again. Remember the symbols, functions, and variables it defines.
This code was evaluated in a python3 interpreter and returned
{result}
Substitution works identically to the Generated Code Executed Prompt.
Prompts and Determinism
In the fifteen years I’ve been writing code this is the first time I’ve come across anything like the paradigm of prompts. In the same way that Lisp treats code as data, LLM applications treat natural language prompts as code. It’s a fundamentally different model of programming to what we’re used to. There’s no API to follow, just instruction and imagination.
Although powerful, LLMs instructed through natural language are very frail. Changing the wording in the prompt could result in radically different behaviour, both in terms of the logic the LLM applies, or the format in which it returns data. This is made more complex by the non-deterministic behaviour of LLMs 1
. Even when setting the temperature
, a setting that controls how deterministic the generated responses are, to 0 the LLM still often replies with different answers to the same prompt across sessions.
For remotely hosted LLMs like ChatGPT, a separate concern is if the LLM itself is swapped out or upgraded without us knowing. Models will have optimisations and compromises, and be trained on different data sets. When an LLM is upgraded will my prompts respond in the same way? This highlights the importance of being able to pin a model version, and raises the question for engineers – how do we validate prompts across different LLMs?
From a software engineering perspective this lack of determinism is a problem. Today’s quality engineering practices such as unit tests and mocking seem inappropriate to validate natural language prompts on LLMs. As the technology evolves I see there being a greater demand for deterministic responses from LLMs. Toy Python REPLs are one thing, but medical and financial applications will have greater demands on the behaviour, predictability, and reliability of LLM responses.
Prompts in Software Engineering
Construction of the prompt is also informal. Over time we’ll see best practices emerge. Some patterns exist today such as prompting the LLM to parse unstructured text and return data in a structured format like JSON. I can imagine a future where prompts become constructed through formal APIs in an ORM or fluent-style interface. This would allow for easier testing and to smooth out differences and features across LLMs.
Prompt.new
|> Accepts.types [(code: string); (result: string)]
|> Accepts.from_prompt "The user has executed code and the result of that code being evaluated in a python3 interpreter"
|> Must "do not run this code again"
|> Must "remember the symbols, functions, and variables it defines"
|> Returns ()
When I write software systems I start with type definitions. These are the core of the system and the rest of the code describes and enables this data to change over time. Implementation and logic emerges around the types, and I can then build the system in a maintainable manner. In writing GEPL the prompts seemed as important as the types. Less-so about the data format a given prompt returns, but more on the phrasing of the natural language that makes up the prompt. This equivalence of importance was reflected in the implementation, where prompts sit in equal importance to types.
The engineering paradigm functional core, imperative shell gives us sensible guidance to keep the core of our systems free of side effects and to push all state management to the edge of the application. Systems which call out to an LLM as a simple API would use this architecture. GEPL is tightly coupled to the LLM. I noticed that the core is actually the prompts, and the types need to react and wrap to whatever it is the LLM returns.
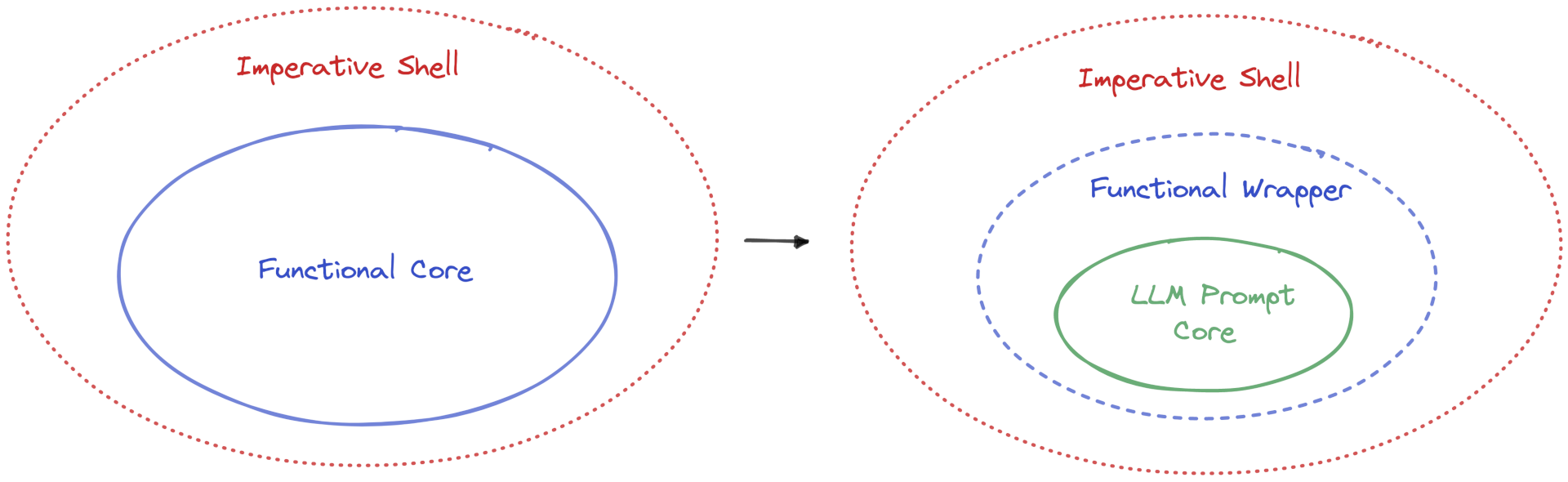
Speculating on future architectures. Prompt core, functional wrapper, imperative shell.
LangChain is the first mover as an open source framework in which to build Python or Typescript applications that interact with LLMs. It’s what I used with GEPL, and allows you to abstract away from anything specific to a given vendor (OpenAI, Azure, Google, etc). OpenAI is the elephant in the room. They have both the most powerful LLMs, as well as the most mature APIs for interacting with the models. As Google and Amazon ramp up their availability of LLMs I expect to see some push and pull between the vendor APIs and LangChain.
Undefined Behaviour
Decades of work has gone into developing debugging and observability tools for computer systems. With LLMs we start again from scratch. LLMs are complex black boxes which take in a prompt and return an answer.
Here’s an example of unexpected behaviour that I ran into while writing GEPL.
Below is an early version of the initial prompt. Key line bolded.
You are a python code generator. Write well-written python 3 code.
The code you generate will be fed into a REPL. Some code and symbols may already be defined by the user.
If you cannot return executable python code return the value NOOP
If you generate a function do not call it.
Return executable python3 code and a description of what the code does in the format:
STARTDESC description ENDDESC
STARTCODE code ENDCODE
My thinking was that if the LLM can’t generate code then it should return a value like an exit code. This would be distinct from the success case of returning STARTDESC and STARTCODE blocks that I can parse. I test it out, and throw some unanswerable prompts at it and see that it’s working as intended.
2023-07 Follow up: Prompting GPT Models to Return JSON
Back to normal development, and I start seeing NOOPs where I don’t expect them.

This sequence of commands returns a NOOP.
Starting a brand new GEPL and calling the set x to 10 without the print worked fine. Why would it consistently fail to generate code for set x to 10 after I printed the integer 10?

This works on its own.
At this stage I think that the LLM thinks that it cannot generate code for the simple task. Unlike every other computer API in existence we can prompt the LLM to tell us why it responded in the way it does. I replaced the bolded line of the prompt with:
If you cannot return executable python code return set the reason why in the description and return no code.
Re-ran, the problematic sequence of commands, and ChatGPT explains itself.

Now the LLM tells us why it can't generate the code.
There’s a peculiar asymmetry here. The same complexity that allows the LLM to tell us why it can’t do something also drives the reason why it can’t do it in the first place.
For this particular task it mistakenly thinks that it has already executed this line of code, and for some reason this prevents it from generating it again. Despite the former being false, I would still not expect the behaviour of “It is not necessary to run it again” to emerge. This could be fixed by tweaking the prompt template to tell it that it can, but without running into this bug I wouldn’t have predicted it emerging.
Conclusion
Prompt-powered LLMs are a new paradigm in software engineering. It expands the class of systems we think are possible to make, but introduces inherent complexity and risk. On one hand we get massive benefits – behaviour that would otherwise be thousands of lines of code to implement, and systems which can tell us why they can’t do something. On the other hand we need to deal with the fragility that is prompts, and the behaviour of LLMs to do things even when unprompted.
Working on this project was a lot of fun. If you’re a software engineer I highly recommend trying out LangChain, LLMs, and experimenting with prompts.
Full source code of GEPL is available on Github .
2023-07 Follow up: Prompting GPT Models to Return JSON
Further Reading
- LLM Engineering - Chip Huyen.
- Exploring ML and AI - Sam Witteveen
- Chat Models - LangChain.