Hypothesis: How engineers go about delivering code to production has an outsized impact on development and long term maintainability of the system.
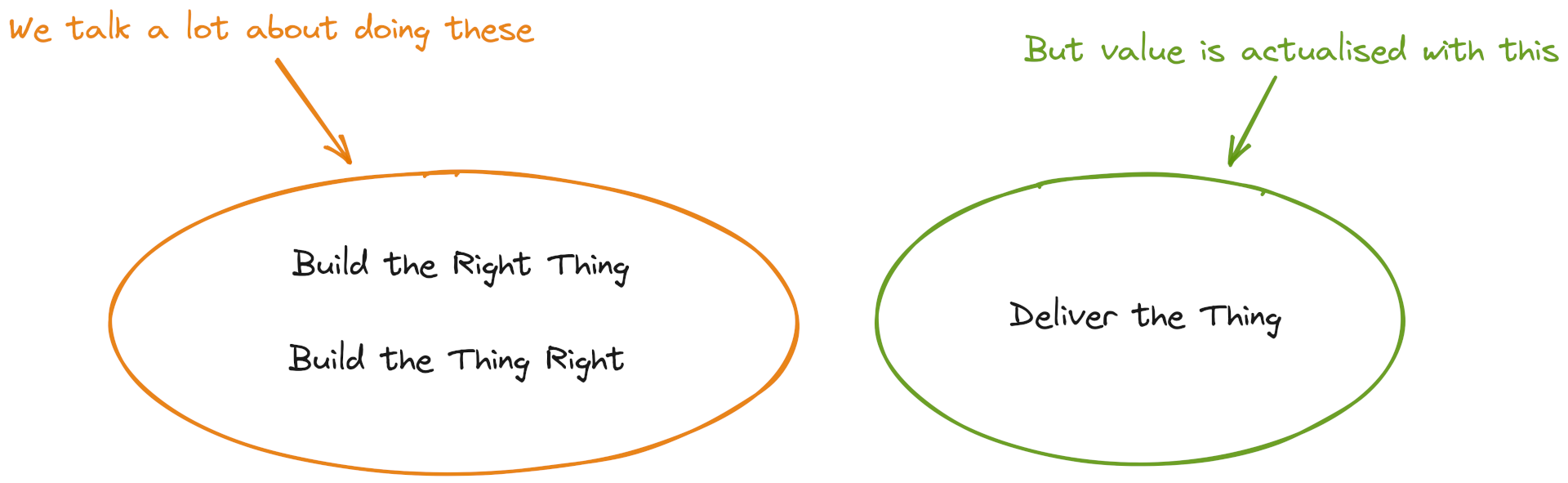
As Software Engineers we often talk about the frames of Building the Right Thing and Building the Thing Right. Both contain a number of practices:
Building the Right Thing
- Product discovery
- User research
- Design
- Prototypes
- A/B testing
Building the Thing Right
- Architecture
- Software design patterns
- Testing
- Code reviews
- Version control
- Documentation
We can carry out all of these and still have generated no value for the customer. Value is only realised when whatever we create is in production in front of users. Code that’s not in production is worthless.
Another lens to look at this idea is around a software system’s architecture. Many textbooks and talks treat system architecture as Building the Thing Right this includes programming languages, frameworks, Design patterns, internet protocols, resilience and error handling. We know what a good architecture is, on paper at least, one that is evolvable and can adapt to changes in requirements – the so-called evolutionary architecture.
I take the position that the software delivery aspects of a system are part of its architecture. More fundamental to Building the Thing Right, software delivery dictates how fast and safely (in terms of risk) we can change the system.
A Software Value Stream
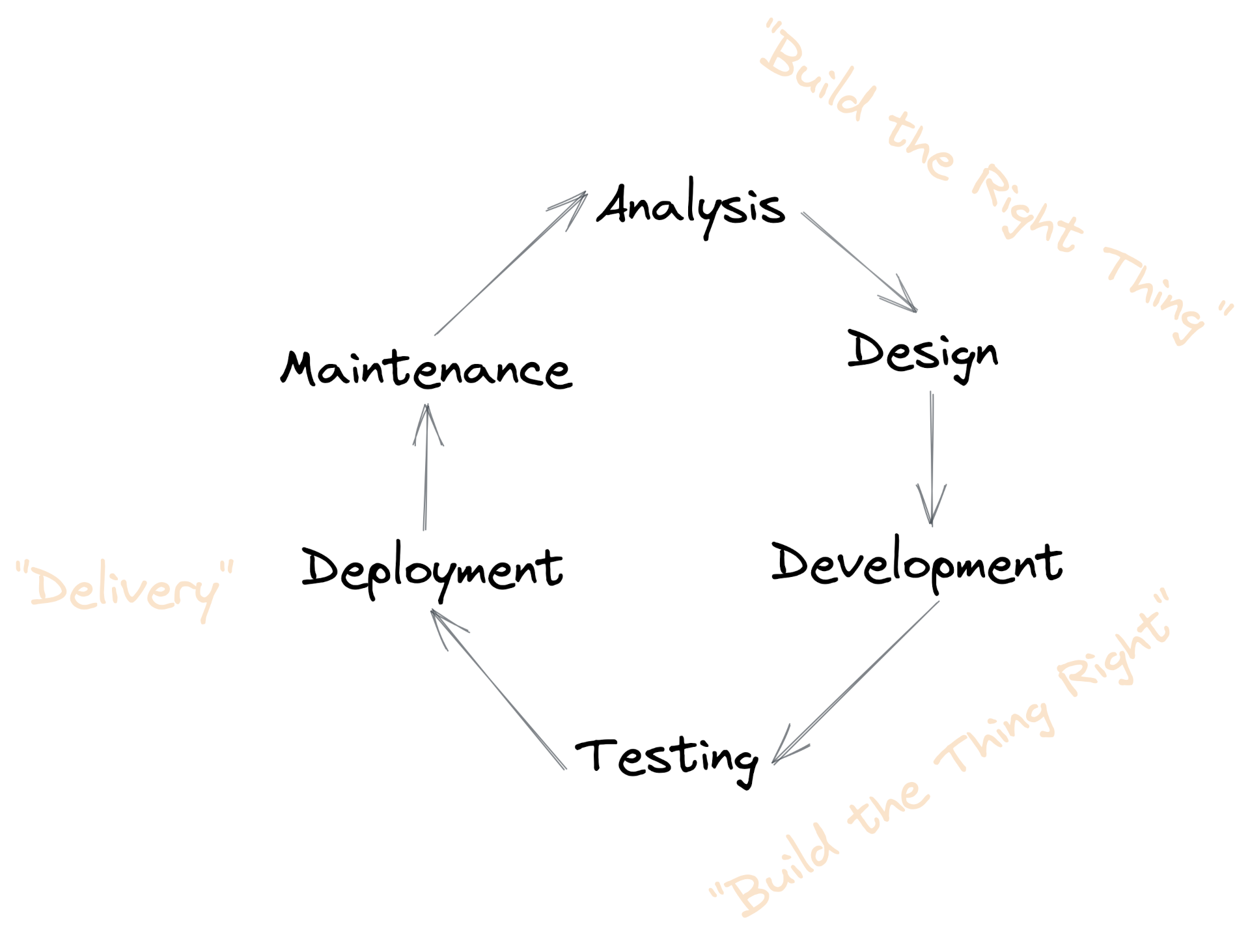
Here’s a simplified software value steam. It describes the steps we take to deliver value to the user. This is just an illustration, the exact steps don’t matter.
We apply this loop at different levels of abstraction, and it might be repeated many times per month, week, or day. This is where the buzzwords of waterfall, agile, scrum and kanban come in, but the internet doesn’t need anything more written about those.
Each of these steps has some sort of cost associated with it. To the company you work for this boils down to a dollar amount, but for us in engineering teams the cost is a sum of time, effort, complexity, risk, and emotion.
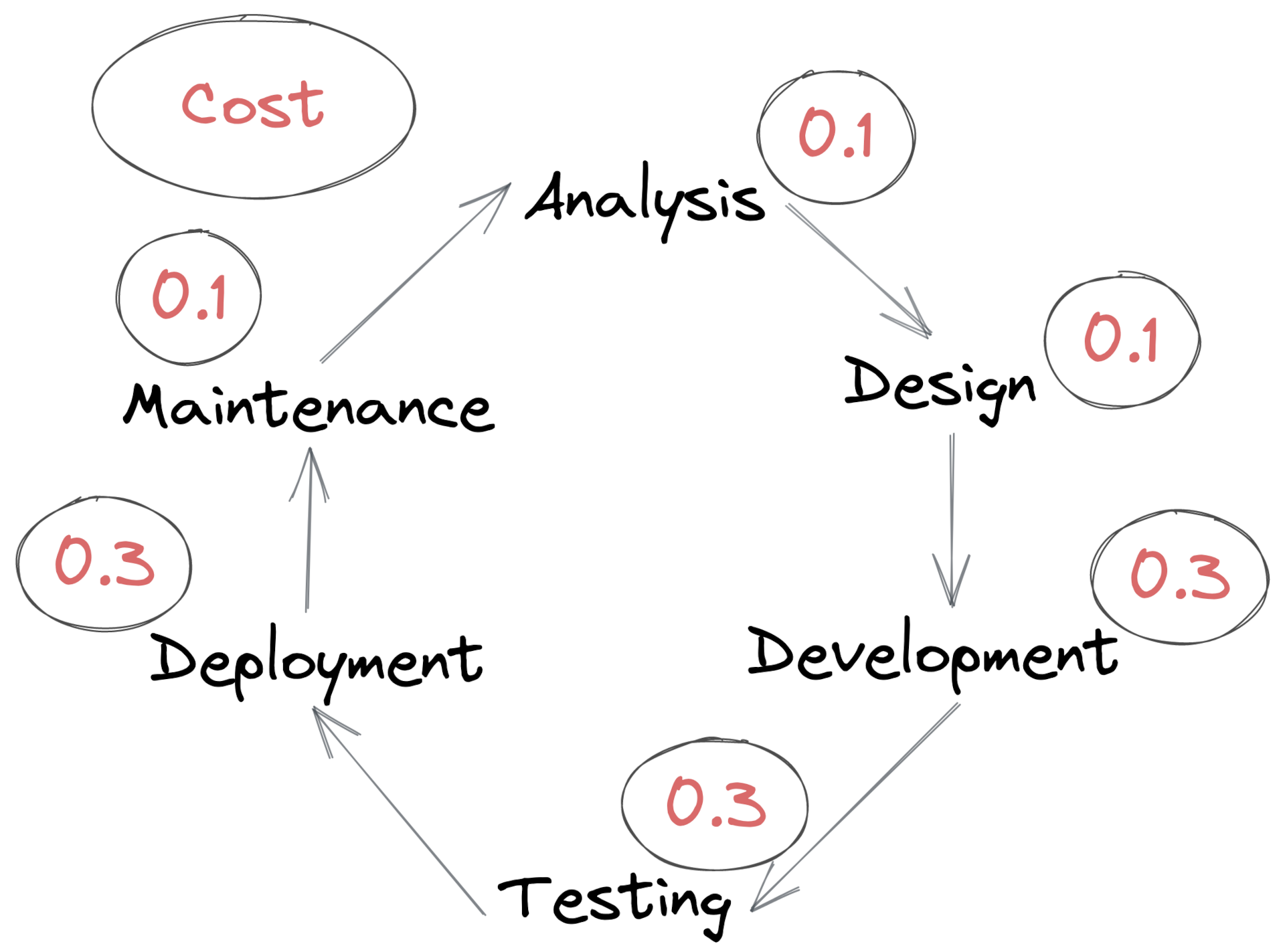
When you’re new to a company or codebase you tend to notice these costs in relative terms. On day one you don’t know the customers, the problems you’re trying to solve, the codebase, nor all of the technologies you’ll be using. At this initial stage the costs of Analysis, Design, and Development will be relatively high. As expertise and experience builds, the costs of all three reduce over time.
But some costs don’t change. Tests and Deployment Pipelines don’t magically get better over time, they’re only ever as good as the time we put into optimising them. The theory of Bit Rot tells us that these actually get worse if we don’t put time into them.
In this frame the costs for Analysis, Design, and Development drift downward, and the costs for Testing and Deployment drift upwards.
Say we want to improve how we write and ship software, where do we start? From teams I’ve been in, the area of improvement typically emerges from lived experience by the engineers. They might find a process such as deployments difficult, so they seek to improve that. Alternatively new engineers to the team might bring practices they’ve used in past projects which solves a particular problem an engineer has. This tends to solve the problems at hand, but may miss larger more impactful improvements.
The textbook way of optimising a Value Stream is to use the theory of constraints. That might work well on a production line, but the work we do is so varied that it’s difficult to accurately measure these over a long period of time. It’s also a very expensive process to run that doesn’t actually improve anything, it only outputs measurements.
What if Deployments were free? My hypothesis is that if deployments took no time, no effort, and no thought, then it would positively impact the other areas in the Value Stream.
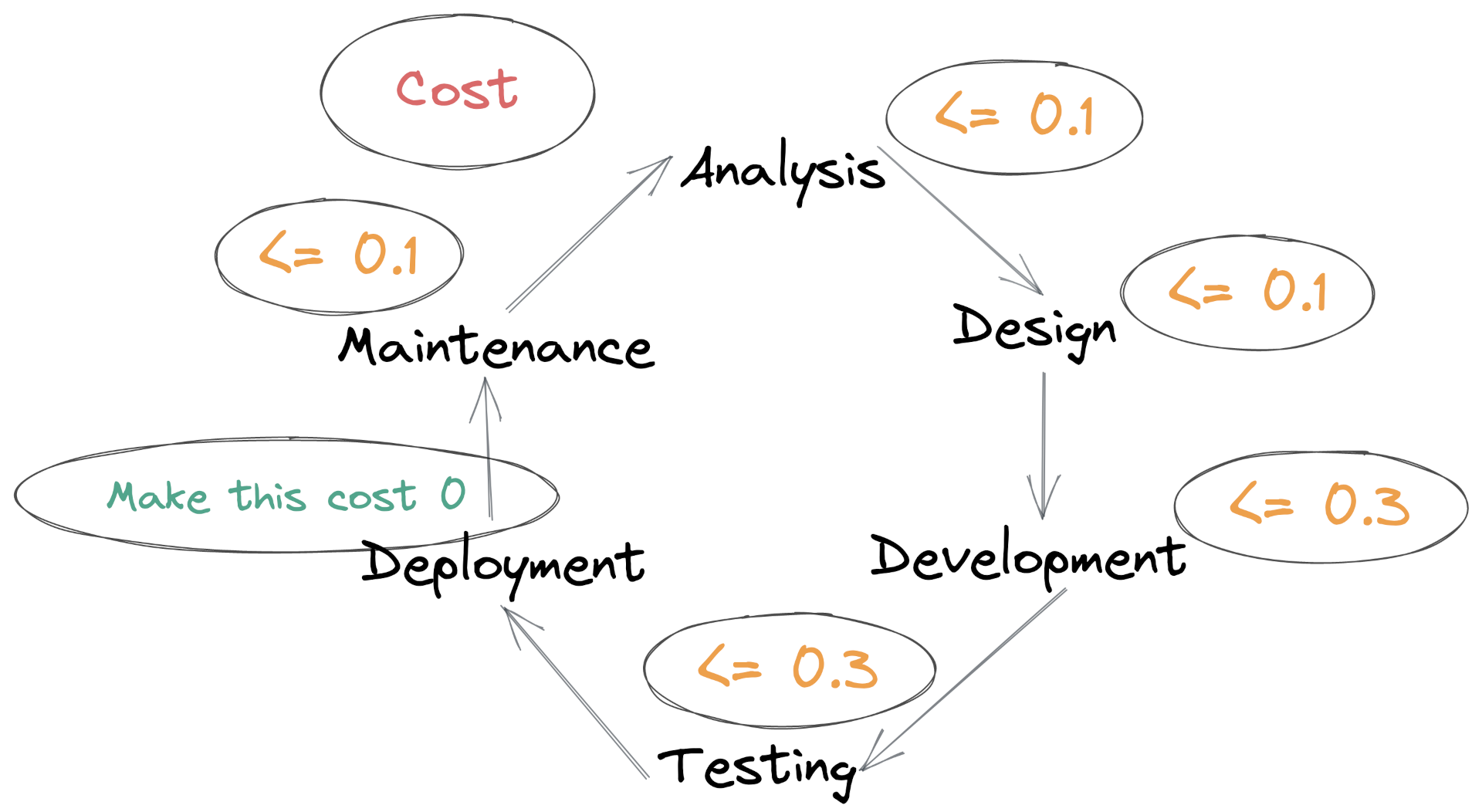
Zero-cost Deployments
A Zero-cost Deployment is completely automated. Engineers are confident in the correctness of the code, the comprehensiveness and consistency of the test suite, the reliability of the deployment pipeline, and the quality of monitoring and alerting that runs in production. With true Zero-cost Deployments people don’t even need to be aware a deployment is happening. This is our goal.
We already have a model where customers shouldn’t know that a deployment is happening – it would imply some noticeable impact on their end. Let’s extend that model to everyone within the organisation as well.
Why focus on the Deployment process and not any of the others? Accelerate (2018) showed the correlative relationship between how a team delivers software (as measured by the DORA Metrics), the stability of their systems, and their status as a so-called high performing team. There’s a lot implied in that term including all of the aspects in the diagram below.
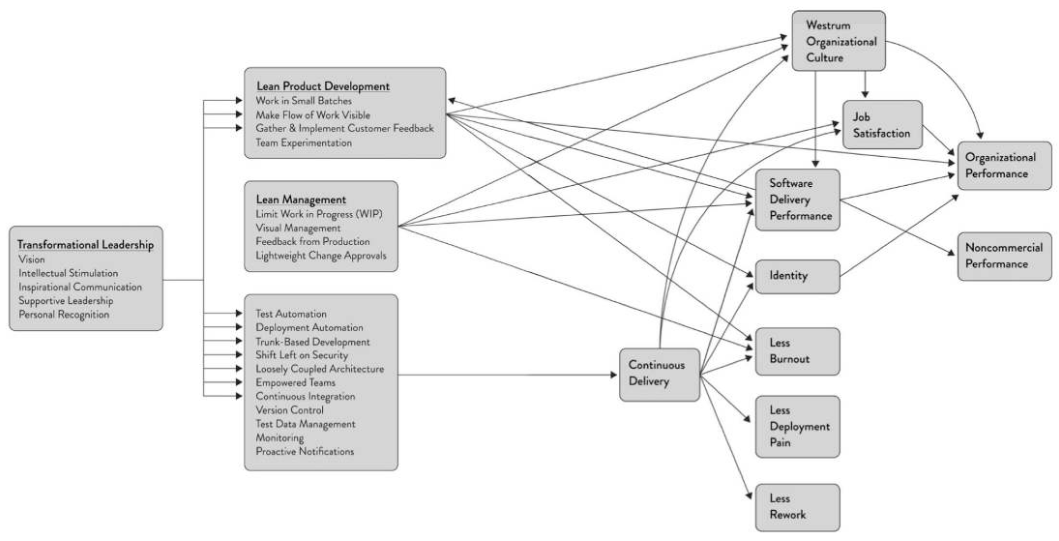
Source: Accelerate
I’ve seen this correlation of a team’s delivery practices and their outcomes play out in the workplace. For the company a high performing team is a return on investment – they ship valuable things quickly and run high quality services. For the individual, being on a high performing team means less burnout, less rework, and more job satisfaction. I’ve experienced both sides of the coin. In one project I worked on I’d often need to spend five hours a day in TeamCity trying to push a deployment through the flakey pipeline. On those days it felt like I didn’t accomplish anything. Contrast that to teams where we’ve had Continuous Deployment or Zero-cost Deployments and that class of frustration just doesn’t exist.
It’s important to call out that external factors often dictate the level of performance a team can achieve. A team operating in a shared codebase using a technology stack from twenty years ago with no unit tests will find it impossible to carry out modern continuous delivery practices. Often organisational priorities, company regulation, or sheer complexity of the task are forces that act against changing the status quo. Beware that the label ‘high performing team’ reflects a lot of the environment in which a team operates, as well as the capability and expertise of the team itself.
Further down we see how implementing Zero-Cost Deployments feeds back improvements into all other processes of the Value Stream and improves software delivery as a whole.
The Cost of Expensive Delivery
A project I used to work took, on average, two hours to deploy. This was a misleading metric, in reality it would take anywhere from 45 minutes in the best case to five hours in the worst case. The five hours was made up of retrying pipeline steps and coordinating with teams whose automated tests had failed in our deployment. Over the months I noticed our team behaviour change from being optimistic in doing a deployment in a couple of hours, to dreading deployments and booking them out in a release calendar. We’d block the whole day for a deployment, initiate it before 9am, and reserve capacity to address problems that inevitably would arise. Worse than that was sometimes we couldn’t even begin a deployment. A set of continuous integration tests ran against a test server every two hours. If any of those tests failed (they were flakey) then policy was to not begin a production deployment until it was green.
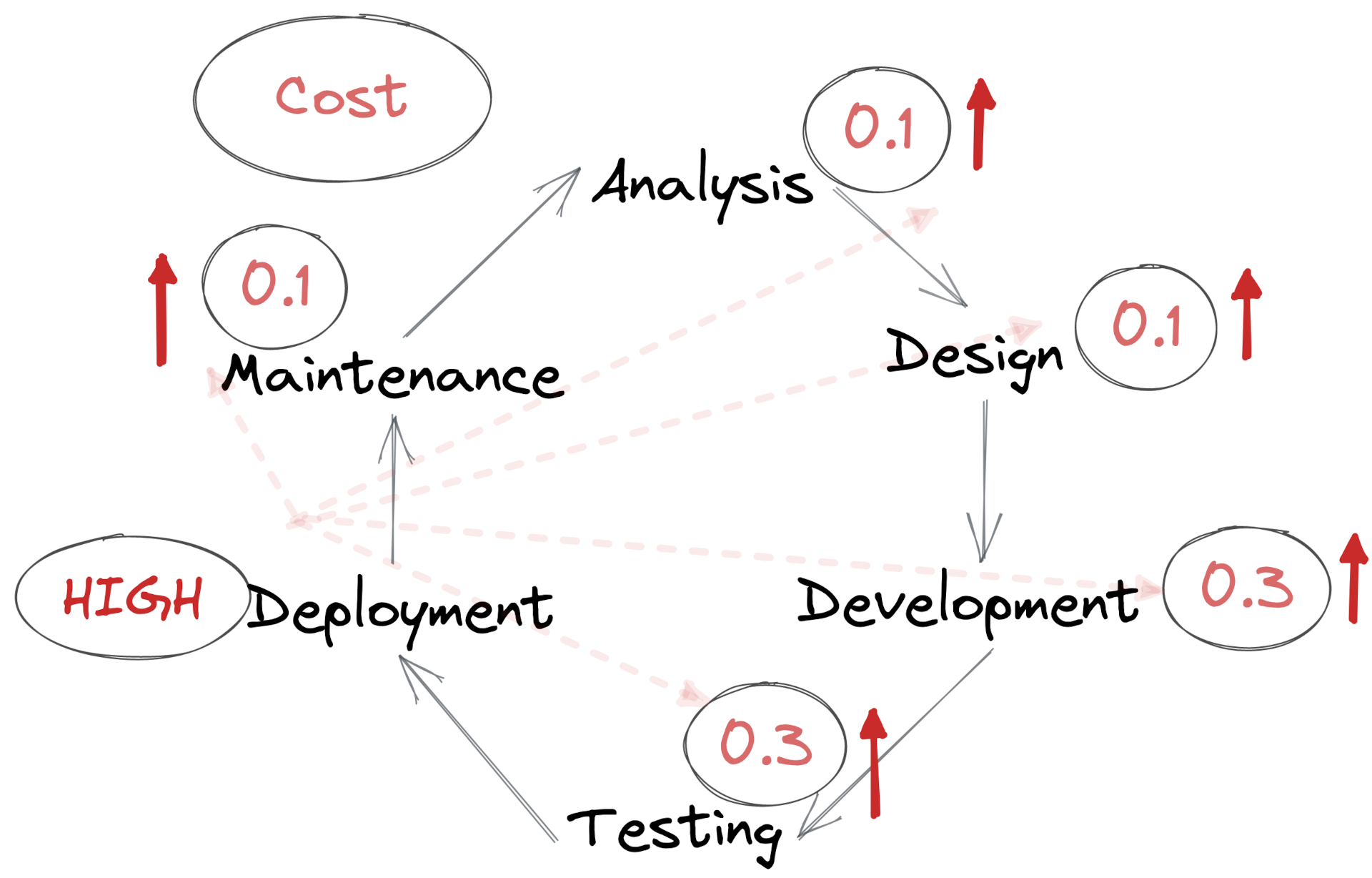
This high cost of software delivery fed back into the other stages of the value stream.
- Analysis & Design. At the time we were doing a lot of testing with customers. We’d visit friendly customers, add them to the beta features feature flag group, and see how they interacted with what we were working on. After a customer interview we’d often want to make some immediate small changes, or set something up as an A/B test for the next interview. The difficulty in deploying sometimes meant we couldn’t get a change out in time.
- Development. With deployments so difficult and costly we’d deploy only when necessary, or wait for one of the other teams that also worked in the codebase to deploy it. This meant sometimes changes would be batched for a week.
- Testing. The difficulty in deploying to production was echoed by the project being difficult to set up and run locally. There was some shared infrastructure (databases), a lot of manual configuration of Windows services, and a very slow edit/debug loop as many dependencies couldn’t be run in a debug mode. Some tests couldn’t be run locally and would only run in CI. This reduced the quantity and quality of tests we wrote.
- Maintenance. When doing business as usual work we often notice areas of the codebase that could be refactored or optimised. A small maintenance code change that would take an hour would be skipped because of the cost to deploy the change.
In this example it was code deployments that inflated the cost of Software Delivery. Be aware that it could be one or several of the other technologies that are in the value stream – code reviews that continue on for days, resolving merge conflicts of long lived feature branches, or manually testing changes.
Improvements with Zero-cost Deployments
On that project, the origin of all pain and suffering was the reality that we were operating in a shared codebase. We could make incremental improvements to the software delivery process, but couldn’t make drastic changes such as moving the project from a feature branching model to trunk based development, or implement continuous deployment due to constraints by other teams.
The cost of software delivery was so high that it was impeding our ability to develop the product. This was recognised by management, and we got the time and space to fix it. This high cost of software delivery was due to a mix of technological factors and team practices. For example we moved the slow-to-deploy API component from .NET Framework on Windows EC2 to Linux containers running on Kubernetes. We also redesigned the CI and CD pipelines from scratch, allowing our team to adopt Continuous Deployment and Trunk Based Development.
This was a game changer for our team. We were now shipping features faster and our engineering practices evolved. Aside from the planned improvements we saw others emerge over time, listed below.
Pair Programming and Mobbing
Before Zero-cost Deployments we would only pair/mob strictly where necessary. This was often to tackle technical problems in the wider monolith or deployment pipeline that only one or two key individuals knew now to solve.
After implementing Zero-cost Deployments we moved to more everyday mobbing practices. The local development and deployment experience was now cost-free. We could test and deploy in the background and it wouldn’t distract from the mobbing session. It was fun to code with others and deploy in real time, and it resulted in more sharing of knowledge and expertise in the team.
Feature Flags
In the old world deployments cost us a whole day. This meant that feature flags were necessary to control the release of features, but no one wanted to spend a day deploying a three line code change to add or remove a flag.
When deployments became free we could do a one minute code change to modify a feature flag and fifteen minutes later it would be in production. This drastic reduction in cost meant that we started using feature flags more, and started flagging partially complete features in production to our close team. By testing in production we gained confidence on what we were writing.
Autonomy
The shared codebase and deployment pipeline had a lot of complexity that wasn’t relevant to our product. This is the type of knowledge that’s vital for at least one person in the team to know but was a waste for everyone to invest time in developing. This led to the situation where we’d depend on individuals for specific changes to the codebase or in debugging deployments.
After implementing Zero-cost Deployments we became more autonomous as a team, but also more autonomous as individuals within our team. The CI/CD setup had been simplified. Anyone in the team could begin a deployment regardless whether they’d been on the team one day or one year. Onboarding new members was easier, and it also encouraged individuals to deploy experiments or trial implementations.
Continuous Delivery & Trunk Based Development
Continuous Delivery is a practice where we build software in a way that can be released to production at any time. If we can release software at any time, and we don’t have regulatory constraints, then we should. The idea of Zero-cost Deployments complements Continuous Delivery and results in Continuous Deployment – once code is merged to trunk it is automatically deployed to production.
Continuous Deployment acts as a self-reinforcing loop to maintain quality in a codebase. Deployments begin automatically – there’s nothing we can do to stop them. This puts an impetus on the code author and reviewers to ensure a given code change has accompanying tests, and also that concerns such as observability and alerting are considered.
Trunk Based Development encourages small, incremental changes to trunk. This reduces the likelihood of change failures (as each change is easier to understand), and reduces toil that emerges from feature branch or environment branching strategies. Zero-cost Deployments makes each code change a deployment and doesn’t add any overhead to the engineer’s experience.
Continuous Delivery and Trunk Based Development require the engineer to work in a certain way because of the longer term payoffs of less rework, less toil, and a more stable code base. Zero-cost Deployments bring immediate value to practising CD and TBD. As soon as each incremental change is made, the code is automatically shipped to production.
Implementing Zero-cost Deployments
Zero-cost Deployments are a simple concept to understand – deployments are fully automated with no human intervention or validation required. Implementing them is more difficult, especially for existing and older codebases. Below are some prompts that will take you closer to Zero-cost Deployments. These are based on my own experience implementing them, and seeing other teams adopting the same idea.
- Deployment pipeline steps that require intervention. We want pipelines to run end to end with no human input. Do any steps require intervention? Eg. starting the pipeline, quality gates, or promotion of particular resources to a production environment.
- Deployment pipeline steps that require coordination. Once code has been reviewed it should go straight to production. We want to eliminate things such as getting the ‘OK’ to deploy from a senior engineer or product manager (use feature flags to release), and complexity in the pipeline which requires multiple people present.
- CI/CD pipeline steps which are flakey. Even if they fail 1% of the time, the engineering team expects them to fail 80% of the time. This adds toil and stress. Flakey steps often indicate tests which need to be improved or removed, or reliance on third party systems which need to be addressed.
- Confidence in Deployments. Are all engineers in the team confident to deploy a system? This will highlight areas to improve.
- Change Failures. Examine change failures that were shipped to prod in the last few months. How could some of these failures have been caught in the CI/CD pipeline? This might indicate areas of testing and observability that can be automated.
- Observability. Once code is deployed, do people often go and check production to validate the change? This is still deployment toil, and could indicate automation that could be brought into the monitoring and alerting stack.
Conclusion
Ultimately, the model of Zero-cost Deployments is another way of looking at Continuous Delivery with emphasis on the costs within the software delivery process. Software Development spans dozens of processes and practices. When seeking to improve how we write software we’re often faced with innumerable choices where the value of each isn’t clear. Zero-cost Deployments clearly puts Software Delivery as the focus. Measuring, understanding, and reducing the cost of software delivery makes a system easier to change, and from here further development, refactoring, and maintenance becomes easier.